前回の記事:C++0x Memory Model 第0回 - メモリモデルとは何か
以下では, C++0x プログラミング言語の標準規格として一貫して N3225 を参照しています.文中で (1.9/12) などという表現が出てきた場合は N3225 における条項を指しています. 太字かつ斜字体の言葉 は N3225 で C++0x で定義される用語, 太字の言葉 は本ブログエントリ中で特別な意味を持たせた用語として定義しているものです.
第1回目のこの記事では,まず,ただ1つの 実行スレッド thread of execution だけを考慮した場合のメモリモデルに関わる基本的な事項を説明していきます.複数スレッドが存在する状況下でのメモリモデルに関する説明する上で,単一の実行スレッド内に限定した場合の状況を把握しておくことは必要不可欠なのです.
第0回において,プログラム中にただ1つの実行スレッドしか存在しない場合には,プログラマがほとんどの状況で無意識に置いている仮定がメモリの読み書きに対して成り立つと言いました.この無意識の仮定をちょっと言葉にしてみましょう.
単一の実行スレッドにおいてはプログラムは記述された順に動作する.
一見すると至極当然のことを言い表した一文で,もちろんこの一文は真です……と言いたいところです.しかし,当然に成り立つと思われるこの一文にメスを入れていくことは非常に重要なのです.この一文のいくつかの部分に細かくツッコミを入れていくとすぐにいくつかの疑問点が出てきます.
- 「実行スレッド」とは何か?
- 「記述された順」とは何か?
- 「記述された順」というのが何か分かったとして「その順に動作する」とはどういうことか?
- 「単一の実行スレッドにおいては」ということは複数の実行スレッドがある場合には「記述された順に動作しない」のか? 仮に「記述された順に動作しない」とするならばそれはどういった理由からか?
- プログラムが「最適化」の対象となる場合にはどうなるのか? そもそも「最適化」とは何か?
ただ1つの実行スレッドのみを考慮した場合におけるこれらの疑問点に C++0x の言葉で真摯に答えていくことは極めて重要です.なぜなら,これらの疑問点に答えていくことで,複数の実行スレッドがある場合のメモリの読み書きにおいて重要な用語や概念が自然に導入されていくからです.
C++0x における「プログラム順 program order」 - sequenced-before
いくらか話を簡単にするために,以下,登場人物を少し限定しましょう.以下では スカラー型 scalar type のオブジェクトのみに限定して話を進めます.スカラー型とは, char や int など, C++0x において最も単純で基礎的な型のグループを指す言葉です.どれほど複雑で巨大なユーザ定義型のオブジェクトに対する操作を実行するにしても,どれほど複雑で長大な関数を実行するにしても, C++0x の範疇では,これらの操作は最終的にすべからく,スカラー型に対する操作か,あるいは環境が用意する何らかの API (関数) 呼び出しか,からなる列に還元されます*1.したがって,ここでの説明をスカラー型に対するものに限定しても必要十分なものとなります.環境が用意する API 呼び出しに関しては通常の関数呼び出しに関する規則が適用されます.あとはその規則を正確に展開し積み重ねていくだけで, C++0x の標準規格の範疇で書かれたあらゆるプログラムに関する動作に関する規定を演繹することができます.
もう1つ,説明の便宜上,しばらくの間「最適化」についての話は脇に置いておくことにします.最初に,「最適化」について考慮しない前提で説明を進めた後,その説明に対して「最適化」についての話を加えていくことにします.
まず最初に 制御の流れ flow of control という言葉について定義しておきます. C++0x におけるある制御の流れとは,各々の条件分岐においてどの分岐を取るかの選択の集合である,と定義しておきます.ここで,「条件分岐においてどの分岐を取るか」とは,つまり if, switch, while, do 〜 while, for の各文の各実行,および各々の仮想関数呼び出しにおいてプログラムコード上のどこへ分岐するかの選択のことに他なりません.
制御の流れが1つ与えられ,全ての条件分岐における選択が定まっていれば,ある関数からどの関数が直接あるいは間接に呼び出されるかも定まります.いくつかの関数は複数回の呼び出しの対象となります.これら各々の関数の各々の呼び出し全てに関して,それらの関数の定義におけるオブジェクトの初期化および式の評価の集まりも一意に列挙することができます.したがって,制御の流れが1つ与えられれば,その制御の流れに含まれるオブジェクトの初期化と式の評価の集まりがただ1通りに定まります.なお,制御の流れに含まれるオブジェクトの初期化や式の評価の中にはコード上に陽には現れないものもあります.
ここで, 式 expression と式の 評価 evaluation という2つの言葉の使い分けに注意してください.式は C++0x に定められた構文上の要素であり,コード上の部分文字列を指します.一方で,制御の流れによっては,ある式に対して評価が存在しなかったり,ある式に対して複数の評価が存在することがあります.たとえば,複数回呼び出される関数の定義に含まれる式や繰り返し文のブロック中の式は複数回の評価の対象となります.
以上を踏まえて 実行スレッド thread of execution という言葉を定義します.実行スレッドとは,ある関数呼び出しを最上位とするある1つの制御の流れのことを指します.制御の流れが一意に定まったとき,そこに含まれるオブジェクトの初期化および式の評価の集まりがただ1通りに列挙することができると説明しました.したがって,1つの実行スレッドに対して,それに含まれるオブジェクトの初期化および式の評価の集まりもただ1通りに定まります.このようなオブジェクトの初期化や式の評価には,最上位の関数呼び出し以前に行われるものや,呼び出しの完了以降に行われるもの,コード上に陽には現れないオブジェクトの初期化や式の評価も含まれます.
通常の説明では,「糸」という意味を持つ「スレッド」という言葉通り,オブジェクトの初期化や式の評価の列,つまり何らかの前後関係が定められた集まり,を含むものとして実行スレッドを説明する場合が多いです.しかし,ここではオブジェクトの初期化や式の評価の単なる集まりを含む,とだけしておきます.これら,オブジェクトの初期化や式の評価の集まりに関する「前後関係」は後で導入します.
例えば, C++0x の範疇で書かれたプログラムの実行に際しては,少なくとも1つの実行スレッド,俗に言う メインスレッド main thread ,が存在することになります.メインスレッドは,典型的には main という名前を持つ特別な関数の呼び出しを最上位とするある1つの制御の流れです.また,メインスレッドには,最上位の関数呼び出しから直接あるいは間接に呼び出される関数全てに関して,それらの関数の定義におけるオブジェクトの初期化と式の評価を全て列挙したものが含まれます.メインスレッドには,最上位の関数呼び出し以前における静的大域変数の初期化などや,最上位関数の呼び出しが完了して以降における静的大域変数のデストラクタ実行も含まれます.また,一時オブジェクトの構築や破壊,関数パラメタの初期化など,コード上に陽には現れないものも含まれます.(5/1)
しばらくの間,以下で示すコード片においてはただ1つの実行スレッドしか存在しないものとして説明を展開していくことにします.以下,式の評価などといった言葉を用いる際には,暗黙に想定しているただ1つの実行スレッドに関して言及していることを常に意識しておいてください.複数の実行スレッドについて考える場合には,たとえば式の評価などといった言葉は「どの実行スレッドに含まれる評価であるか」を明示する必要があります.
具体的なプログラムを例として説明を進めます.
int main() {
int x = 2; // (1)
int y = 0; // (2)
y = (x == x); // (3)
return 0; // (4)
}上のプログラムにおける x = 2, y = 0 はオブジェクトの初期化です.また, 2, 0, x, x == x, y = (x == x) はそれぞれ式です.上のプログラムを実行した際のオブジェクトの初期化と式の評価の集合は以下の通りです.
2 // (1) x = 2 // (1) x の初期化 0 // (2) y = 2 // (2) y の初期化 x // (3) における等号演算子の左辺 x // (3) における等号演算子の右辺 x == x // (3) y = (x == x) // (3) 0 // (4)
オブジェクトの初期化や式の評価に関する「前後関係」についてはまだ何も説明していませんから上で列挙しているオブジェクトの初期化や式の評価の並び順は今のところは特に意味がないものと思ってください.これらが,先のプログラムがある1つの実行スレッド T によって実行された際の, T による式の評価の集合となります.
しつこいようですが,今の段階においては,オブジェクトの初期化や式の評価に関する「前後関係」のようなものをまだ一切定義していないことに注意してください.したがって,どのオブジェクトがどの順番で初期化されどの式がどの順番で評価されるかは今の段階では何も説明できません.「オブジェクトの初期化や式の評価はプログラムコードの上の行から下の行に向かって行われていく」などといったことはまだ一言たりとも述べていません.どのような順でオブジェクトが初期化され式が評価されるのかは以下に述べる規則が全てです.そして,オブジェクトの初期化や式の評価の順序を述べていないということは,必然的に式の評価によって値を読み込んだ際にどういった値が読み込まれるかもまだ一切説明できない段階だということです.
次に,オブジェクトの初期化と式の評価という言葉をより掘り下げていくことにします.一般に,オブジェクトの初期化と式の評価は「読み」と「書き」から成り立ちます.「読み」とは 値の計算 value computation のことであり,「書き」とは 副作用の開始 initiation of side effect のことです.式の評価における値の計算とは,その式が左辺値ならばそれがどのオブジェクトを指しているかを同定すること――平たく言えばオブジェクトのアドレスの算出――と,式が表している値を取り出すこと,を指します.また,オブジェクトの初期化や式の評価における副作用の開始とは,オブジェクトの初期化や式の評価の結果生じる 実行環境の状態 state of execution environment の変化――平たく言えば,たとえばメモリ上に記録されている値の変化など――が開始されることです.(1.9/12, 5/1)
再び,先ほどのプログラムを例として説明を進めます.たとえば (3) の代入式の右辺における式 x の値の計算には, x という式がどのオブジェクトを指しているのかの同定――平たく言いなおせばオブジェクト x のアドレスの計算――と, x に対して代入されている値の取出しが含まれます.この式 x の評価は副作用を開始しません.また,他の例として (4) の代入式 y = (x == x) の評価においては,左辺の式で同定されたオブジェクト y に対して,右辺の式 x == x で取り出された値が代入されるという副作用が開始されます.また,この代入式の値の計算として代入先のオブジェクト (つまり y) が再び同定され (代入式は代入先のオブジェクトの左辺値を返すことを思い出してください),式の値 (つまり代入後の y の値) が取り出されます (代入式の値は代入結果の値であることを思い出してください) .先ほどのプログラムにおける副作用の開始と値の計算を列挙すると以下のようになります.
2 の vc // (1) の初期化子 initializer の評価 x = 2 の se // (1) による初期化 0 の vc // (2) の初期化子の評価 y = 2 の se // (2) による初期化 x の vc // (3) における等号演算子の左辺 x の vc // (3) における等号演算子の右辺 x == x の vc // (3) y = (x == x) の se // (3) y = (x == x) の vc // (3) 0 の vc // (4)
ここで, vc は値の計算 (Value Computation) , se は副作用の開始 (initiation of Side Effect) の略であるとします.この略号は以下でも使用します.先と同様,やはりこの段階でも上の表における値の計算と副作用の開始の並び順には特に意味はありません.
以下,値の計算と副作用の開始の2種類をまとめて アクション action と呼ぶことにします.
ある1つの実行スレッドにおけるアクション間の「前後関係」に相当する用語を導入しましょう.ある1つの実行スレッドにおけるアクション A と B を考えます.あるアクション A が別のアクション B よりも先行することを アクション A がアクション B に対して sequenced-before である (an action A is sequenced before an action B) ということにします.どのアクションがどのアクションに対して sequenced-before であるかは,各アクションがどの構文要素に対応したものであるかを元に, C++0x の記述から正確に定めていくことができます.ただし,ある1つの実行スレッドにおけるすべてのアクションのペア A と B に対して,「A が B に対して sequenced-before である」か,「B が A に対して sequenced-before である」か,を常に定められるとは限りません. A が B に対して sequenced-before でもなく, B が A に対して sequenced-before でもないとき, A と B は unsequenced である,ということにします.
さて,アクションは値の計算と副作用の開始の2種類であると定義しました.この説明の最も重要な部分は,アクションには副作用の開始だけが関連付けられているということです.開始されたものはいつかは完了されなけれなりません.ある実行スレッドにおけるアクション A で開始された副作用がどの時点まで完了していることが保証されるかは, A を含む実行スレッド内に関して限定すると, sequenced-before という言葉を用いて明確にすることができます. A があるアクション B に対して sequenced-before であるとき, A で開始された副作用は B までに完了していることが保証されます.
sequenced-before についていくつか説明しておきます. sequenced-before は,2つのアクションからなる順序対 ( (A, B) と (B, A) とが区別されるペア) に対して真偽を与える関数と見なすことができます.このことを特に強調して, sequenced-before はアクション上の 2項関係 である,と言うこともできます.以下,特に注記することなく, sequenced-before を2項関係として,あるいは単に 関係 として言及することにします. sequenced-before 関係は同じ実行スレッドにおけるアクション間においてのみ真になりえます.2つのアクションが異なる実行スレッドにおけるものであるときにはそれら2つのアクションは常に unsequenced となります.定義から,任意のアクション A に関して, A は A 自身に対して sequenced-before ではありません.この性質を特に指して 非反射的 irreflexive であると言います.また,同じく定義から,任意の異なる2つのアクション A, B に関して, A が B に対して sequenced-before ならば B は A に対して sequenced-before ではありません.この性質を特に指して 非対称的 asymmetric, antisymmetric であると言います.また,同じく定義から,任意のアクション A, B, C に関して, A が B に対して sequenced-before であり, B が C に対して sequenced-before であるならば, A は C に対しても常に sequenced-before となります.この性質を特に指して 推移的 transitive であると言います.以上, sequenced-before 関係は,非反射的で,非対称的で,推移的で,いくつかのアクションのペアに対してどちらの方向にも成り立たない関係となります*2.このことを特に指して 厳密な半順序 strict partial order であるなどと表現します*3 *4.
以下,メモリモデルに関する多くの事柄は,言葉で延々と書かれたものを読むよりも,図を用いた説明のほうがずっと分かりやすいものになります.アクション A が アクション B に対して sequenced-before であることを次のように図示することにします.
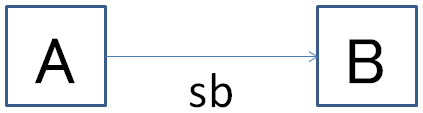
今,下図のような4つのアクションに対する sequenced-before 関係を考えます.
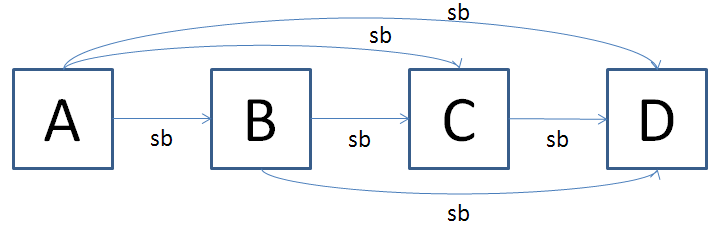
この図に表されている sequenced-before 関係がきちんと厳密な半順序になっていることを確認しておいてください.さて,このままだと多くのアクションが図中に登場したときに sb の矢印が多くなりすぎます.そこで一定のルールで sb の矢印を省略することにします. sequenced-before 関係の推移性を用いることで他のアクション間の sequenced-before 関係から導出できる sequenced-before 関係を全て省略することにします.たとえば,先ほどの4つのアクションが登場する図に対しては sb の矢印が次のように省略されます.
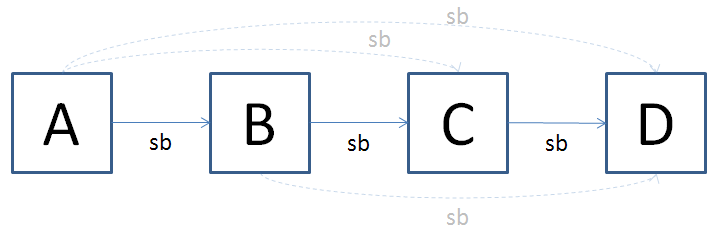
この省略を 推移簡約 transitive reduction と呼び,推移簡約の結果できるこのような図のことを特に ハッセ図 Hasse diagram と呼びます.逆に,ハッセ図から2つのアクション間に sequenced-before 関係があるかどうかも簡単に確認することができます.アクション A から sb の矢印を向きに従ってたどって行ってアクション B にたどり着けるならば A は B に対して sequenced-before である,ということが分かります.以下では, sequenced-before 関係を図示する際には常にハッセ図の形で描くことにします.
ここに至って,先ほどのプログラムを実行した場合の各式の各評価がどのような順序で行われるかの説明にようやく入ることにします.プログラムコードと対応するアクションの集合を以下に再掲します.
int main() {
int x = 2; // (1)
int y = 0; // (2)
y = (x == x); // (3)
return 0; // (4)
}a: 2 の vc // (1) の初期化子の評価 b: x = 2 の se // (1) による初期化 c: 0 の vc // (2) の初期化子の評価 d: y = 2 の se // (2) による初期化 e: y の vc // (3) f: x の vc // (3) における等号演算子の左辺 g: x の vc // (3) における等号演算子の右辺 h: x == x の vc // (3) i: y = (x == x) の se // (3) j: y = (x == x) の vc // (3) k: 0 の vc // (4)
行頭のアルファベットは各々の値の計算や副作用の開始を本文や図中で言及できるようにするための名前付けです.このアクションの集合に対する sequenced-before 関係を図示したものが以下です.
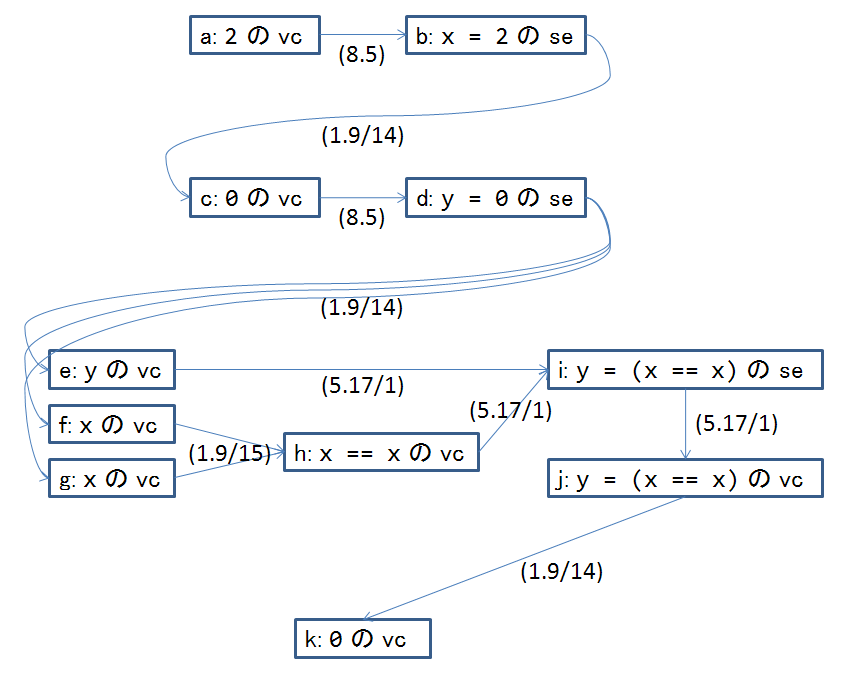
図中の矢印はすべて sb ラベルを省略しています.また,図中の各矢印に付けているのは各 sequenced-before 関係の直接的な根拠となっている C++0x ドラフト N3225 の条項です.この例のようにして,ある1つの実行スレッドに含まれるアクションの集合に対して, C++0x が定める規則から sequenced-before 関係を付与していくことができます.1つの実行スレッド上のアクションの集合に対して,このようにして付与されたある sequenced-before 関係が C++0x における プログラム順 program order ということになります.
sequenced-before 関係の定義のところで述べましたが, C++0x においてはある1つの実行スレッド上の全てのアクションのペアに対して sequenced-before 関係が付与されるとは限りません.これを unsequenced と言いました.ある2つのアクション A と B とが unsequenced である場合, A は B に対して先行するか, B は A に対して先行するか,あるいは A と B の実行が一部または全部重なり合うかの,いずれかとなります.上のプログラムの例では,例えば e, f, g の3つのアクションの間には sequenced-before 関係が一切存在しません.したがってこの3つのアクションは,任意の順序で実行されることも,2つ以上のアクションの実行が一部または全部重なり合う形で実行されることも,いずれもが許されることになります.ここで,現在の説明の段階では「最適化」の話を脇に置いていることに注意してください.「最適化」が許されていない状況下でもこのようなことが許されるわけです.
上の例で見られるように, C++0x では,複数のアクションの実行順序が任意であったり,複数のアクションの実行が一部または全部重なり合っても許されます.この具体的な意味づけについて少しだけ説明しておきます.以下のコード片を例として説明します.
int x = 0; int y = 1; int z = 2; y = x++ + y + ++z; // (A)
上のコード片における (A) に含まれるアクションに対する sequenced-before 関係は以下に図示する通りとなります.各矢印の sb ラベルは省略します.
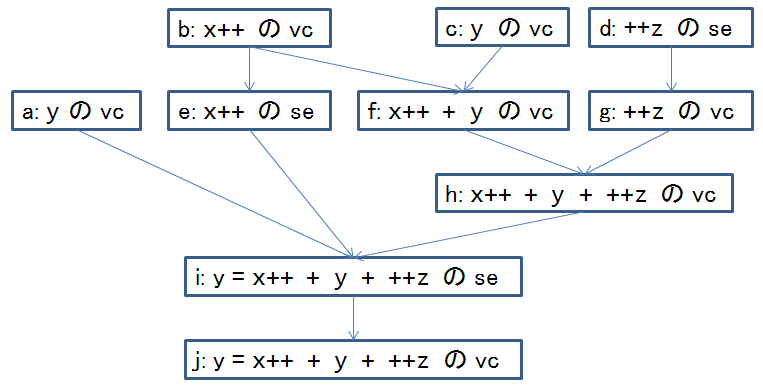
上のコード片がある実行スレッドによって実行される際には, (A) 中の式 x++ の評価に対する副作用の開始 e は,式 y = x++ + y + ++z の評価に対する副作用の開始に対してさえ sequenced-before 関係を維持していれば良いことになります.したがって,式 x++ の評価に対する値の計算は式 y = x++ + y + ++z の評価に対する副作用が開始されるまでにさえ完了していれば良いことになります.結果,この式 x++ の評価に対する副作用の開始が, C++ のコードがある特定のコンパイラ実装によって機械語に翻訳される様子,およびその翻訳結果の機械語が実際のある特定のアーキテクチャ上で実行される様子は,その制限さえ充足していればどのようであっても構わないことになります.たとえば,式 x++ の評価に対する副作用の開始がコンパイラによって対応する機械語に翻訳される際に,式 y の評価に対する値の計算に対応する機械語の後ろに配置されることが許されるわけです.また,たとえば,式 x++ の評価に対する副作用の開始に対応する機械語の実行と,式 ++z の評価に対する副作用の開始に対応する機械語の実行が,アーキテクチャ上で並列に行われても構いません*5.ある式が複数回評価される場合に,各評価毎に異なる順序,異なる方法を取ることすら許されます.これによって,コンパイラによる翻訳の自由度,およびアーキテクチャ上の機械語の実行の自由度を非常に高い状態で維持できることになります.
最後に,現行の C++ プログラミング言語の標準規格である C++03 における表現との対応について簡単に触れておきます. C++03 では,上記で説明したような内容は 副作用完了点 sequence point と呼ばれる用語を用いて規定されていました.しかし, C++0x で厳格なメモリモデルの記述を導入するにあたって,副作用完了点という用語は廃止され,上記で説明した sequenced-before 関係を用いた記述に刷新されました.副作用完了点という用語が廃止された理由としては,
- いくつかの状況におけるアクション間の順序に関して,これまで副作用完了点という用語による説明では不明瞭だったことが,上記の sequenced-before 関係による説明で明確になるから
- 上記のような半順序関係による説明の方が,後の説明で明らかとなりますが,そのまま複数の実行スレッドがプログラム中に存在するときの記述に自然に拡張できるから
というのが挙げられます.これまで副作用完了点という用語で説明されてきたことはすべて, sequenced-before という用語による説明によって上位互換な形で置き換わっています.
単一スレッド上のデータ競合 - unsequenced race
先に述べたとおり,いくつかのアクションの実行は,その順序が任意であったり,一部または全部が重なり合っていることが許されます.このことは,先に述べたようにコンパイラによる機械語への翻訳の自由度やアーキテクチャ上の機械語の実行の自由度を確保します.一方で,世間一般によく知られたある種の 未定義の振る舞い undefined behavior を引き起こす直接的要因を生み出すことにもなります.
unsequenced な異なる2つのアクションが同じオブジェクトに対するアクションである場合を考えます.これら2つのアクションが「読み」「読み」である場合には特に問題はありません. unsequenced な2つのアクションが同じオブジェクトに対して値の計算を行うことは C++0x においては許されています.問題は少なくとも一方が「書き」の場合です.
あるオブジェクト M に対して,ある副作用 S が開始されて以降その完了が保証されないタイミングで, M に関する値の計算を行うこと,あるいは M に対して別の副作用を開始すると未定義動作を引き起こします. S の完了が保証されないタイミングにおいては, S はすでに完了しているか,まだ開始されていないか,あるいは最悪の場合は M は S の完了に向けた中途半端な状態にあるかであり,このどれであるかは,上述の通り,機械語への翻訳を行うコンパイラ,および機械語を実際に実行するアーキテクチャ,それらの完全な裁量に委ねられています. M に対する副作用が完了していることが保証されないタイミングで, M に関する値の計算を実行したり, M に対して別のさらなる副作用を開始すると非常に具合が悪いことは明らかでしょう.したがって, C++0x においてはこのような状況を一括して未定義動作を引き起こすものとして規定しています.
具体的な例として以下のコード片について詳しく見ていきます.*6
void g(int i, int *v) {
i = v[i++]; // (A)
/* ... */
}(A) がある実行スレッドで実行されたときの,各アクション間の sequenced-before 関係を以下に図示します.各矢印の sb ラベルは省略します.
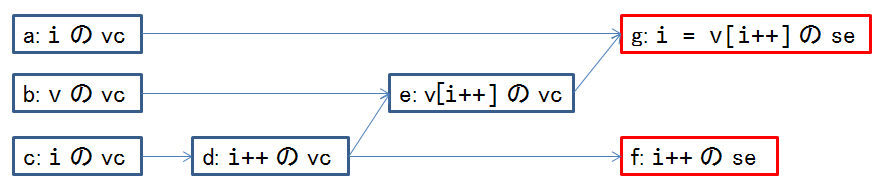
g と f の2つのアクションは unsequenced であり,両方ともに i に対して副作用を開始します.このような場合,例えば g による i に対する副作用が開始されるタイミングでは, i に対する f の副作用は,すでに完了しているか,まだ開始されていないか,もしくは f の副作用は開始されているがまだ完了しておらず i は中途半端な値を持つか,のいずれかです.逆に, f の副作用が開始されるタイミングの観点から見てもまったく同様の議論になります.これは先に述べたように非常に具合が悪く, C++0x ではこのような状況は未定義動作を引き起こすものとして規定されています.
未定義動作を引き起こすこの種の状況を,以下, unsequenced race と呼ぶことにします.
unsequenced race が引き起こされる条件を,先に定義した用語を用いて表現しておきましょう.2つのアクションの片側から見てもう一方が引き起こした副作用が完了していない状態というのは,結局のところ,これら2つのアクションの間に sequenced-before 関係がどちらの向きにも存在しない場合になります.したがって, unsequenced race が引き起こされる条件は,2つのアクション A と B が以下のすべての条件を満足するときとなります.
- A と B とが unsequenced である
- A と B 両方が同じオブジェクトに対するアクションである
- A と B のどちらかが副作用の開始である
なお,現行の C++03 では 未指定の振る舞い unspecified behavior を起こすとされていたいくつかの状況が, unsequenced-before 関係による規定に変更されたことに伴い, C++0x では一括して未定義の振る舞いを起こすものとして規定が変更となっています.
「最適化」とは何か? - observable behavior と as-if ルール
ここまでの説明は「最適化」の話を一切脇に置いて説明してきました.以下では,上記までの説明に「最適化」に関する説明を加えていくことにします.
C++0x におけるプログラムの 最適化 optimization とは, C++0x の範疇で書かれたあるプログラムコードに対して,上述の制約を満たした機械語への翻訳結果とアーキテクチャ上における機械語の実行方法――C++0x プログラミング言語の実装――が得られたとき,それに対してある観点からは見分けのつかない別の C++0x プログラミング言語の実装に変換する行為である,とここでは定義することにします*7.ここで,「2つの C++0x プログラミング言語の実装の見分けが付く・付かない」がどの観点から定義されるかが問題となります. C++0x では「プログラミング言語の実装の見分けが付く・付かない」についての観点は, 観測可能な振る舞い observable behavior という言葉で定義されます.
観測可能な振る舞いについて説明します.観測可能な振る舞いとは,プログラムを実行した際に,ユーザが観測することが前提となっている挙動です.たとえば,メモリのどの場所へどのような順序でどのような値が書き込まれたかは観測可能な振る舞いではありません*8. C++0x で定義されている観測可能な振る舞いは以下の通りです.
volatile修飾されたオブジェクトに対するアクセスの評価- プログラム終了時のファイルへの出力結果
- interactive device の入出力の挙動において,入力を待つ前に入力を促すための出力をきちんと表示すること
今, C++0x の範疇で書かれたあるプログラムコードに対する C++0x プログラミング言語の実装が2つあるとして,観測可能な振る舞いだけ見てもそれら2つの違いが分からないとき,この2つの C++0x プログラミング言語の実装は「見分けが付かない」と呼ぶことにします. C++0x では,あるプログラムコードの C++0x プログラミング言語の実装は,「見分けが付かない」ものならばどれであっても構わないと規定されています.この規定を特に as-if ルール と呼びます.「最適化」とは, as-if ルールの範囲で許される C++0x プログラミング言語の実装の候補のうちの適当な1つを選択することだということができます.
複数の実行スレッド間の関係を説明するにあたって
以上の説明は,ただ1つの実行スレッドが存在する場合についてのものでした.ここでは,それらの説明が複数の実行スレッドが存在する場合の話へどうつながっていくかについて簡単に触れておきます.
sequenced-before 関係の説明においては, sequenced-before 関係はある1つの実行スレッドに含まれる異なる2つのアクションに関してのみ真になりえると説明しました.また, sequenced-before 関係は,あるアクションが開始した副作用がいつまでに完了するかについての保証をもたらすとも説明しました.ここから得られる1つの帰結として,異なる実行スレッドに含まれる2つのアクションの間においては,何か特別なことをしない限り副作用の完了に関する保証が一切得られない,ということが挙げられます.
unsequenced race の説明においては,あるオブジェクトに対する副作用が完了していることが保証されていないタイミングで,同じオブジェクトに関する値の計算や別の副作用の開始を行うことが未定義動作を引き起こすと説明しました.ところで,マルチスレッドプログラミングにおける データ競合 data race という用語をご存じの方も多いかと思います. C++0x では,この,あるオブジェクトに対する副作用が完了していることが保証されていないタイミングで,同じオブジェクトに関する値の計算や別の副作用の開始を行うことをまさにデータ競合と定義しています.したがって, unsequenced race は単一実行スレッド下におけるデータ競合の特殊形であると説明することができます.ということは,逆に, unsequenced race という概念・用語を理解すること,あるいは,その成立条件を構成する値の計算,副作用の開始・完了, sequenced-before 関係などの概念・用語を理解することはそのまま C++0x におけるデータ競合の概念を理解することにつながっていきます.
最適化の説明においては,コンパイラによってプログラムコードが機械語に翻訳された結果,そして翻訳結果の機械語が実際のアーキテクチャ上で実行される様子は,観測可能な振る舞いを変化しない範囲ならばどのようであっても完全に自由だと説明しました.ここで, C++0x で規定されている観測可能な振る舞いを思い出してください.何か特別なことをしない限り,ある実行スレッドにおけるアクションが他のある実行スレッドにおけるアクションに対してどのような影響を与えるかは観測可能な振る舞いの範疇には一切入りません.したがって,最適化は,何か特別なことをプログラム上でしていない限り,観測可能な振る舞いに影響のある sequenced-before 関係,つまりある実行スレッド上のプログラム順のみを考慮し,それ以外のあらゆる観点で複数の実行スレッド間の関係を一切考慮しないことが許されます.結果として,複数スレッド間の関係に関する特別な何かをプログラムコード上で明示しない限り,最適化は複数の実行スレッド間の関係に対して完全に予測不能な結果をもたらすことになります.ただし,このことは一方で,単一実行スレッドのためにこれまでに積み上げられてきた膨大な量の各種最適化実装の資産とノウハウを完全に継承することができるということも意味します.
複数の実行スレッドがある場合に volatile 修飾子がどのような効果をもたらすかについても説明しておきます.上に述べたとおり, volatile 修飾子によって対象のオブジェクトに対するアクションは観測可能な振る舞いとして扱わなければならなくなります.したがって, volatile 修飾子が付与されたオブジェクトに対するアクションは, as-if ルールの適用外となり, sequenced-before 関係に厳密に従う形態で実装されなければなりません.しかし,それだけです.前述のとおり, sequenced-before 関係は同一実行スレッドにおけるアクションだけにしか成り立ちません.したがって, volatile 修飾子は異なる実行スレッドにおけるアクション間の関係には一切寄与しません.結果, volatile 修飾子に複数の実行スレッド間の関係に関する何らかの効果を期待することは基本的にできない,という結論になります.
以上の説明を踏まえた上で,複数の実行スレッドが登場する場合について順次説明していくこととします.
(次の更新は多分1ヶ月以上後です.)
*1:厳密には ビットフィールド bit field についても説明する必要がありますがここでは省略します.
*2:非反射的で推移的であれば必ず非対称的であるため,非対称的であることを述べるために sequenced-before 関係の定義に言及することは必ずしも必要ではありません.
*3:「厳密な strict」という言葉は,非反射性のことを指しています.「厳密な」という言葉を入れずに,単に 半順序 partial order という言葉で同じ意味を指すこともあります.
*4:同じ内容を指す他の用語として 非反射的な半順序 irreflexive partial order や strict preorder といったものがあります.
*5:筆者はハードウェアレベルの話にはあまり明るくないですが,単一の実行スレッド上でアクションが並列に実行されるというのは,例えばアーキテクチャ上の機械語の実行における instruction-level parallelism が想定されます. instruction-level parallelism に関しては,例えば "Computer Architecture, Fourth Edition: A Quantitative Approach" の2章などを参照してください.
*6:1.9/15 の example から引用.
*7:ある C++0x プログラミング言語の実装に対して,そのような変換は一般に無数に存在します.実際上は,「最適化」とはその変換の中から実行速度やプログラムサイズ等の観点から見て適当な1つを選ぶことを指す言葉になります.
*8:もちろん,実行環境によってはこれらの振る舞いもユーザの観測対象となる場合がありますが,依然として C++0x の観測可能な振る舞いではありません.